Opcache 介绍
Opcache 呢。它的目标是提供一个自由、 开放,和健全的框架用于缓存和优化PHP的中间代码。
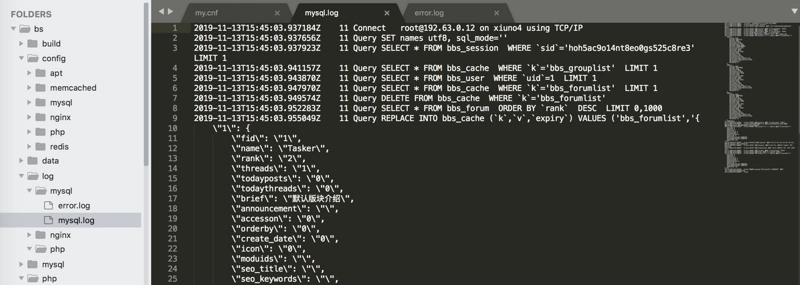
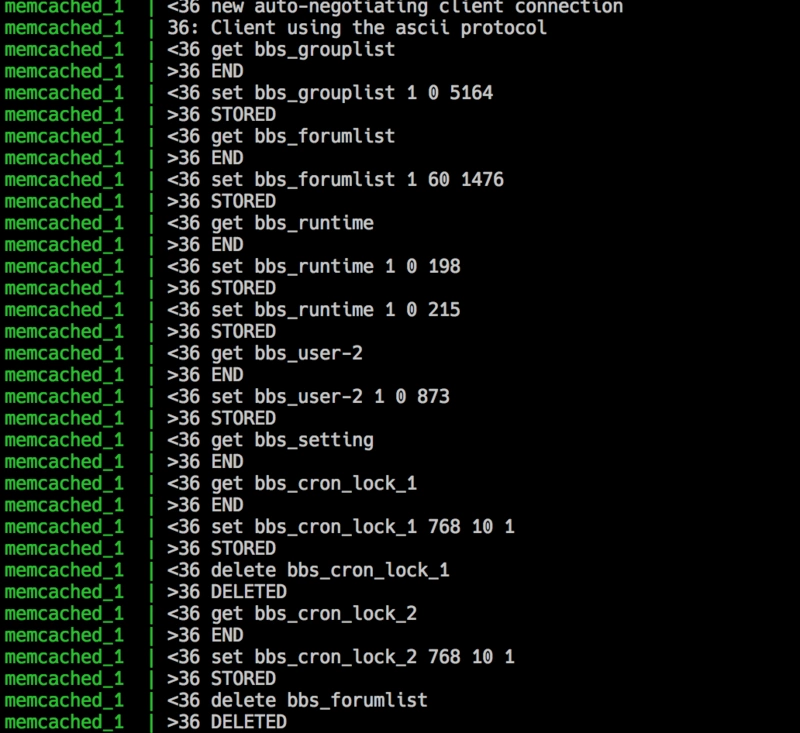
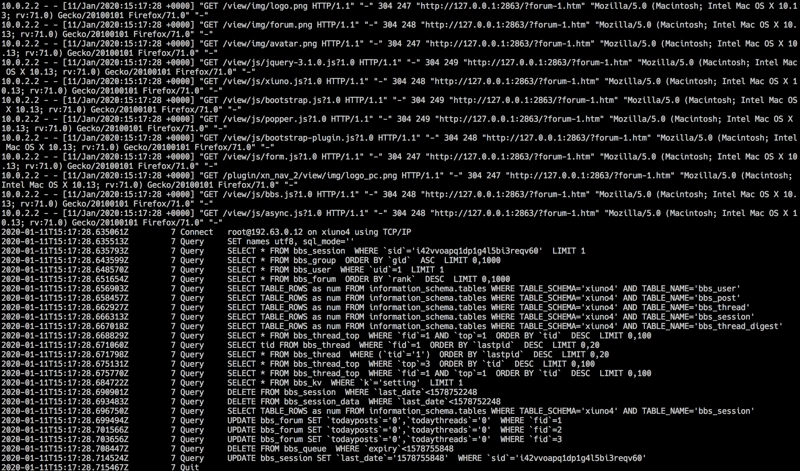
OPcache 通过将 PHP 脚本预编译的字节码存储到共享内存中来提升 PHP 的性能, 存储预编译字节码的好处就是 省去了每次加载和解析 PHP 脚本的开销。
PHP 5.5.0 及后续版本中已经绑定了 OPcache 扩展。 对于 PHP 5.2,5.3 和 5.4 版本可以使用 » PECL 扩展中的 OPcache 库。
— 摘自 PHP.net
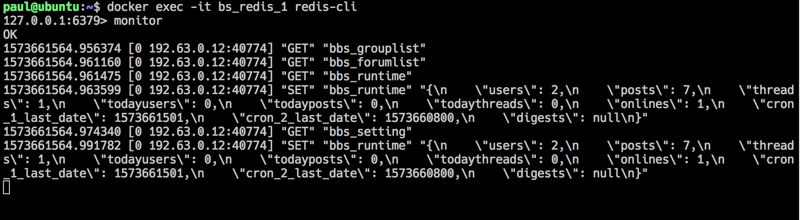
注意,它和 Alternative PHP Cache (
APC) 是一个开放自由的PHP opcode 缓存,是两个东西,别搞混了。
安装
PHP 5.5.0 及后续版本
OPcache 只能编译为共享扩展。 如果你使用 --disable-all 参数 禁用了默认扩展的构建, 那么必须使用 --enable-opcache 选项来开启 OPcache。
编译之后,就可以使用 zend_extension 指令来将 OPcache 扩展加载到 PHP 中。
PHP 5.4 以及更低版本
在 pecl 下载安装
运行时配置
/php/php.ini
[opcache]
; dll地址
zend_extension=php_opcache.dll
; 启用该拓展打开
opcache.enable=1
; 在cli模式页开启opcache加速
opcache.enable_cli=1
; 可用内存, 酌情而定, 单位为:Mb
opcache.memory_consumption=128
; Zend Optimizer + 暂存池中字符串的占内存总量.(单位:MB)
opcache.interned_strings_buffer=8
; 对多缓存文件限制, 命中率不到 100% 的话, 可以试着提高这个值
opcache.max_accelerated_files=4000
; 启用,那么 OPcache 会每隔 opcache.revalidate_freq 设定的秒数 检查脚本是否更新。如果禁用此选项,你必须使用 opcache_reset() 或者 opcache_invalidate() 函数来手动重置 OPcache,也可以 通过重启 Web 服务器来清空
opcache.validate_timestamps=0
; Opcache 会在一定时间内去检查文件的修改时间, 这里设置检查的时间周期, 默认为 2, 设置为 0 会导致针对每个请求, OPcache 都会检查脚本更新。单位:秒。
opcache.revalidate_freq=60
; 打开快速关闭, 打开这个在PHP Request Shutdown的时候回收内存的速度会提高
opcache.fast_shutdown=1
; opcache 不保存注释,减少opcode大小
opcache.save_comments=0
; 启用或禁用在共享内存中的 opcode 缓存。
opcache.file_cache_only=0
;设置不缓存的黑名单
; opcache.blacklist_filename=/png/php/opcache_blacklist
; 配置二级缓存目录并启用二级缓存。 默认值为空字符串 "",表示禁用基于文件的缓存。
opcache.file_cache=/var/www/html/php_cache/
; opcache.file_cache=/var/www/php/cache
更多配置见: php.net
配置好之后,我们运行phpinfo试试看。

如果能看到这界面,说明这个拓展装好了,
注意看到标红,这个说明命中次数,为啥7次呢,因为这个页面我刷行了7次。
使用
opcache_compile_file
该函数可以用于在不用运行某个 PHP 脚本的情况下,编译该 PHP 脚本并将其添加到字节码缓存中去。 该函数可用于在 Web 服务器重启之后初始化缓存,以供后续请求调用。
<?php
/**
* @params string $file 被编译的 PHP 脚本的路径。
* @return boolean 便已成功否
*/
function opcache_compile_file ( string $file ) : boolean
注意事项,Opcache 倾向于编译面向对象编程的代码。并且是在不运行脚本的情况下去编译,也就是它不会判断该脚本在运行时,哪些代码肯定会被执行,哪些不会被执行。也不会判断你的代码执行顺序。它会假设你的代码都会被执行,所以,一些函数的重复定义,会报错。
opcache_invalidate
该函数的作用是使得指定脚本的字节码缓存失效。 如果 force 没有设置或者传入的是 FALSE,那么只有当脚本的修改时间 比对应字节码的时间更新,脚本的缓存才会失效。
<?php
/**
* @param string $script 缓存需要被作废对应的脚本路径
* @param bool $force
如果该参数设置为TRUE,那么不管是否必要,该脚本的缓存都将被废除。
* @return bool 成功否,如果脚本的字节码缓存失效设置成功或者该脚本本来就没有缓存,则返回 TRUE;如果字节码缓存被禁用,则返回FALSE。
*/
function opcache_invalidate ( string $script [, boolean $force = FALSE ] ) : boolean
opcache_is_script_cached
此函数检查PHP脚本是否已缓存在OPCache中。这可用于更轻松地检测特定脚本的缓存“变化”。
<?php
/**
* @param string $file 需要被检查的脚本路径
* @return bool 如果被Opcache缓存就返回true
*/
function opcache_is_script_cached ( string $file ) : bool
opcache_reset
该函数将重置整个字节码缓存。 在调用 opcache_reset() 之后,所有的脚本将会重新载入并且在下次被点击的时候重新解析。
<?php
/**
* @return bool 如果字节码缓存被重置成功,则返回 TRUE;如果字节码缓存被禁用,则返回 FALSE。
*/
function opcache_reset ( void ) : boolean
使用说明: 该函数不能和 opcache_compile_file 函数在同一个脚本生命周期调用。 reset 需要用脚本单独调用。
实战
<?php
// file: opcach_init.php
define('DS', DIRECTORY_SEPARATOR);
$basePath = $argv[1];
if (empty($basePath)) {
$basePath = __DIR__ . DS . '..' . DS . 'php_project';
}
//opcache_reset(); // 不能先reset,再刷缓存,需要在另外一个脚本运行。
//sleep(2);
opcache_compile_files($basePath);
function opcache_compile_files($dir) {
foreach(new RecursiveIteratorIterator(new RecursiveDirectoryIterator($dir)) as $v) {
if(!$v->isDir() && preg_match('%\.php$%', $v->getRealPath())) {
opcache_invalidate($v->getRealPath(), true);
opcache_compile_file($v->getRealPath());
echo $v->getRealPath()."\n";
}
}
}
PHP cli 模式下运行该命令,就会为该目录,以及子目录下php文件生成Opcache 缓存。
$ php ./opcach_init.php ./../php_project/
cachetool
兼容性
- CacheTool 5.x works with PHP >=7.2
- CacheTool 4.x works with PHP >=7.1
- CacheTool 3.x works with PHP >=5.5.9
- CacheTool 2.x works with PHP >=5.5.9
- CacheTool 1.x works with PHP >=5.3.3
下载
- 从
githup下载cachetool.phar:
- 从 composer 下载
$ composer require gordalina/cachetool
$ composer require gordalina/cachetool:~1.0
使用
$ php cachetool.phar --help
$ php cachetool.phar apcu:cache:info --fcgi
$ php cachetool.phar apcu:cache:info --fcgi=127.0.0.1:9000
$ php cachetool.phar opcache:status --fcgi=/var/run/php5-fpm.sock
$ php cachetool.phar opcache:status --cli
$ php cachetool.phar opcache:status --web --web-path=/path/to/your/document/root --web-url=http://url-to-your-document.root